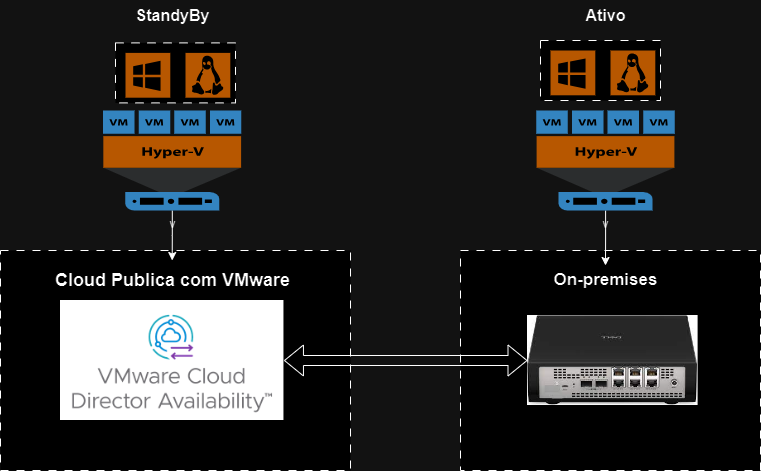
O Cluster Pandora nasceu dentro da Unifique Cloud com um propósito ousado: garantir que a gestão e os serviços críticos do ambiente permaneçam operacionais mesmo diante de falhas severas de storage, rede ou virtualização.
Mais do que um cluster de gerenciamento, o Pandora é um núcleo autônomo e distribuído de controle e orquestração, construído para operar de forma independente e manter a Unifique Cloud sob controle — mesmo quando o resto do ambiente para.
O Desafio
Em uma infraestrutura moderna, quase tudo depende da camada de gerenciamento.
Mas o time da Unifique Cloud percebeu um ponto cego:
“E se o próprio ambiente de controle cair junto com o restante da infraestrutura?”
A resposta foi criar um cluster isolado, resiliente e autossustentável, espalhado por locais físicos diferentes da infraestrutura principal, garantindo continuidade operacional e independência total.
Assim nasceu o Projeto Pandora — o cluster que não dorme.
A Arquitetura
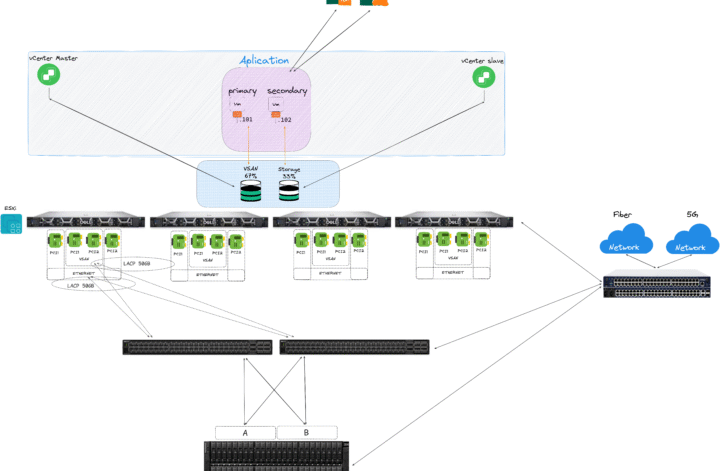
O Pandora foi projetado sobre processadores AMD EPYC, que entregam alta densidade de núcleos, performance térmica eficiente e confiabilidade sob carga constante.
Seu armazenamento é 100% baseado em discos NVMe, garantindo latência ultrabaixa e throughput máximo, mesmo em cenários de operações simultâneas de backup, replicação e orquestração.
Cada host está conectado a todos os Top of Rack (ToR) do datacenter, com uplinks redundantes e um canal WAN exclusivo, permitindo acesso remoto e gestão plena mesmo em situações de isolamento da rede interna.
Além disso, o cluster é geograficamente distribuído, aumentando ainda mais sua tolerância a falhas físicas e elétricas.
O armazenamento roda sobre VMware vSAN configurado em RAID1, assegurando espelhamento de dados entre hosts.
E, indo além da replicação, os serviços foram intencionalmente distribuídos entre o vSAN e storages dedicadas — exemplo: quatro controladores de domínio (AD), sendo dois no vSAN e dois em storage independente.
Mesmo em uma falha total de um dos sistemas de armazenamento, os serviços de autenticação e diretório seguem em operação.
Serviços Críticos Hospedados
O Pandora é o ponto de sustentação da Unifique Cloud, abrigando não só a camada de gerenciamento, mas também serviços de produção utilizados por clientes.
Dentro dele rodam:
- vCenter, VMware Cloud e NSX Manager – o coração da virtualização e SDN.
- Veeam Backup & Replication – Backup Server incluindo o serviço de Cloud Connect entregue aos clientes Unifique.
- Active Directory e PAM – autenticação, segurança e controle de privilégios.
- Kubernetes Cluster e Load Balancer – orquestração e entrega de microsserviços internos.
- Soluções de monitoramento da Cloud – visibilidade completa da operação.
- Portais e dashboards das nuvens – interface de gestão e provisionamento.
- Sistemas de inventário, como o NextBox – controle de ativos e topologia.
Com esse desenho, o Pandora garante que, mesmo durante falhas severas em storages, leafs, spines ou clusters VMware, a gestão, o monitoramento e os serviços críticos continuem operando de forma independente.
O Pandora é um ambiente construído para não ser usado — como um seguro de carro: você espera nunca precisar, mas dorme tranquilo sabendo que está protegido.
Ele existe para garantir que, em um cenário de contingência total, a Unifique nunca fique no escuro.
Mesmo que o ambiente principal sofra interrupções graves, o Pandora mantém viva a inteligência e o comando da operação.
Resiliência Total
O projeto foi desenhado para resistir a falhas múltiplas e simultâneas:
- Falha de storage? Aplicações redundantes continuam disponíveis.
- Perda de leaf ou spine? Conectividade mantida pelos ToRs ativos.
- Clusters VMware fora do ar? O Pandora segue orquestrando o ambiente e coordenando a recuperação.
Os backups seguem a política 3-2-1, armazenados em storage dedicada e replicados para appliance S3 imutável, protegendo contra falhas físicas, humanas e lógicas.
Resultado
O Cluster Pandora consolidou-se como o núcleo de resiliência e governança distribuída da Unifique Cloud.
Mais do que um projeto técnico, ele representa uma filosofia de engenharia:
Alta disponibilidade não é um recurso. É uma mentalidade.
E quando o inesperado acontece, o Pandora está lá — garantindo que a Unifique siga no comando.