Ambientes virtualizados raramente falham no momento da implantação.
Na maioria dos casos, eles entram em colapso meses depois, quando começam a crescer sem que o projeto inicial tenha considerado expansão, picos de consumo e cenários reais de falha.
O quase nunca é a tecnologia, mas sim o modelo mental utilizado no dimensionamento.
Neste artigo veremos um método prático para dimensionar ambientes de virtualização com foco em:
- Estabilidade operacional
- Crescimento previsível
- Facilidade de expansão
- Redução de retrabalho (rework)
Sem fórmulas mágicas, baseado em princípios de arquitetura.
Por que ambientes virtualizados quebram
Os principais fatores que levam um ambiente a degradação é:
- Projeto baseado apenas em capacidade bruta (TB e número de cores)
- Ignorar latência de storage
- Overcommit agressivo sem observabilidade
- Ausência de margem para alta disponibilidade
- Crescimento orgânico sem planejamento
Virtualização não morre por falta de hardware, virtualização morre por falta de arquitetura.
Definição do perfil de workload
Antes de falar em servidor, é obrigatório entender a carga.
Perguntas essenciais:
- Quantas VMs?
- Quantas VMs em 12,24 ou 60 meses?
- Aplicações são CPU-bound, memory-bound ou IO-bound?
- Há workloads sensíveis à latência?
Classificação simples:
- CPU-bound → bancos de dados, aplicações com alto cálculo
- Memory-bound → caches, aplicações Java, analytics
- IO-bound → VDI, bancos de dados transacionais, file servers
Dois ambientes com o mesmo número de VMs podem exigir arquiteturas completamente diferentes.
Dimensionamento de CPU
Princípios:
- vCPU não é core físico
- Overcommit é aceitável, desde que controlado
- Frequência de clock importa tanto quanto quantidade de núcleos
Boas práticas:
- Overcommit conservador: 3:1
- Reservar capacidade para falha de pelo menos um host
- Monitorar CPU Ready
Se o ambiente é crítico, priorize mais hosts médios ao invés de poucos hosts gigantes.
Dimensionamento de memória
Memória é o recurso mais crítico da virtualização.
Princípios:
- Evitar ballooning e swapping
- Considerar consumo do hypervisor
- Considerar cache de storage em memória
Boas práticas:
- Margem livre mínima: 20% a 30%
- Evitar overcommit agressivo
- Padronizar tamanhos de VM quando possível
Gosto de pensar que cpu se gerencia e memória se respeita.
Storage: latência primeiro, capacidade depois
Usuários não percebem IOPS.
Usuários percebem latência.
Aspectos fundamentais:
- Latência média
- Latência em pico
- Perfil de leitura vs escrita
- Aleatório vs sequencial
Boas práticas:
- Separar tiers (NVMe, SSD, NL-SAS)
- Garantir cache adequado
- Monitorar filas de IO
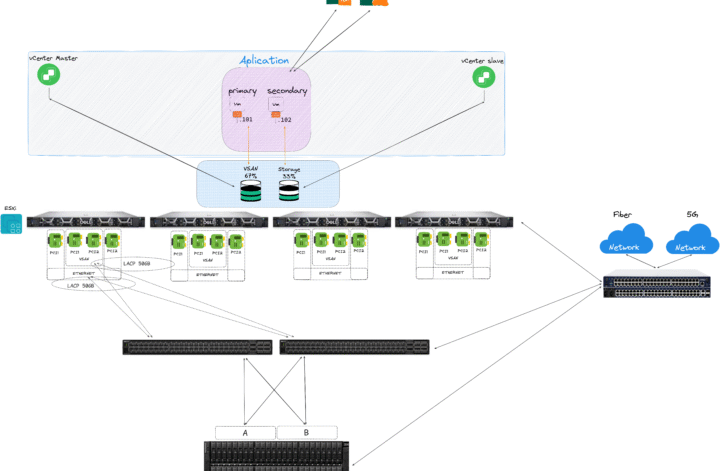
Rede dentro da virtualização
Rede subdimensionada mascara problemas de CPU e storage.
Boas práticas:
- Redundância física
- Separação lógica de tráfego
- Gerência
- Storage
- Migração
- Produção
- Throughput compatível com storage
Evite arquiteturas onde todo tráfego passa por um único uplink.
Alta disponibilidade na prática
Pergunta que deve ser pensanda, se eu perder um host agora, tudo continua funcionando?
Boas práticas:
- Capacidade reservada para falha
- Testes periódicos de HA
- Janela de manutenção considerada no projeto
Regra prática:
HA sem capacidade é apenas reinicialização elegante.
Planejamento de crescimento
Todo projeto deve nascer com:
- Slots livres de expansão
- Licenciamento previsto
Escalar não deve ser um projeto especial.
Deve ser rotina operacional.
Erros clássicos
- Comprar servidor maior em vez de mais nós
- Misturar workloads incompatíveis no mesmo cluster
- Não medir consumo real
- Ignorar latência
- Não testar cenários de falha
Meu pensamento
Muitas organizações investem em servidores de marcas enterprise, como Dell ou Lenovo, contratam 5, 6 ou até 7 anos de garantia e acreditam que isso, por si só, garante longevidade ao ambiente.
Na prática, vemos exatamente o oposto: clusters que morrem com 2 ou 3 anos, não por falha de hardware, mas por mau dimensionamento.
O hardware sobrevive. A arquitetura não.
Um cluster começa a envelhecer no dia em que nasce, e esse envelhecimento é acelerado quando:
- O dimensionamento de vCPU é feito sem critério
- Processadores são escolhidos apenas pela quantidade de cores, ignorando clock base
- Workloads single-threaded sofrem por falta de frequência
- A segmentação lógica de rede é tratada como “opcional”
Dimensionar corretamente vCPU, priorizar CPUs com frequência base mais alta para cargas sensíveis a single-thread e desenhar uma segmentação lógica bem definida (gerência, storage, migração e produção) devem ser decisões tomadas antes da primeira VM ser criada.
É curioso observar que muitas empresas consideram o cluster de virtualização como o ativo mais crítico do negócio, mas não executam sequer o básico — como configurar alta disponibilidade para o vCenter Server.
Sim, o coração do ambiente sem HA.
Se você quer evitar que seu cluster envelheça antes do tempo, o ponto de partida não é o modelo do servidor.
É o desenho.
Me procure para trocar uma ideia e desenhar juntos o melhor cenário.
Ambiente virtualizado bem projetado não é o maior.
Não é o mais caro.
Não é o mais novo.
É aquele que cresce sem surpresa, opera estável e permite expansão sem redesenho.
Arquitetura vem antes do hardware.