One of the more useful features of Windows Server 2012 and Windows Server 2012 R2 is native data deduplication. Although deduplication features have existed in storage hardware for years, the release of Windows Server 2012 marks the first time that Microsoft has allowed deduplication to occur at the operating system level.
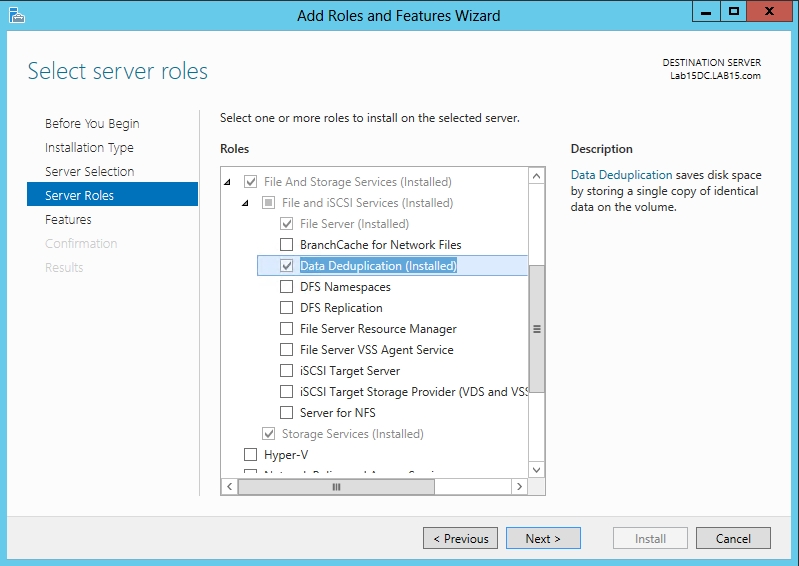
Before you can use the deduplication feature, you will have to install it. To do so, open Server Manager and then choose the Add Roles and Features command from the Manage menu. When the Add Roles and Features Wizard launches, navigate through the wizard until you reach the Add Roles screen. Expand the File and Storage Services role, and then expand the File and iSCSI Services container and select Data Deduplication, as shown in Figure 1. Click Next on the remaining screens and then click Install to install the necessary components. When the process completes, click Close.
Deduplication is performed on a per-volume basis. To do duplicate a volume, open the Server Manager and select the Volumes container. Next, right click on a volume and choose the Configure Data Deduplication command from the resulting shortcut menu, as shown in Figure 2.

At this point the Deduplication Settings dialog box will appear, as shown in Figure 3. You can enable data deduplication by simply selecting the Enable Data Deduplication check box and clicking OK. However, there are a couple of other settings on this dialog box that are worth paying attention to.
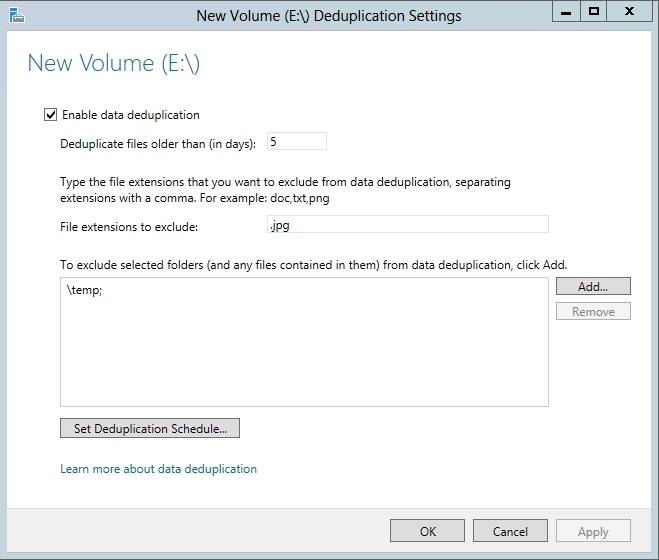
The first such setting is the Duplicate Files Older Than setting. The deduplication mechanism in Windows is post process. In other words, deduplication does not happen in real time. Instead, a scheduled process performs the deduplication at a later time. The reason why Microsoft gives you the option of waiting until a file is a few days old before it is be duplicated is because the deduplication process consumes system resources such as CPU cycles and disk I/O. You really don’t want to waste these resources on deduplicating temporary files. Making sure that a file is at least a few days old before it is deduplicated is a great way to avoid wasting system resources.
Another setting that is worth paying attention to is the File Extensions to Exclude setting. The basic idea behind this setting is that some types of files cannot be deduplicated because they are already compressed. This includes things like zip files, and compressed media files such as MP3 files. The File Extensions to Exclude setting lets you avoid wasting system resources by preventing Windows from trying to do duplicate files that most likely will not benefit from the deduplication process. Similarly, if you have folders containing compressed files you can exclude those folders from the deduplication process.
Finally, there is an option to set the deduplication schedule. You should configure the deduplication process to occur outside of peak hours of operation.
Of course this raises the question of the hardware resources that are required in order to perform data deduplication. The minimum supported configuration is a single processor system with 4 GB of RAM and a SATA hard disk. According to Microsoft, a deduplication job needs one CPU core and about 350 MB of RAM. Such a system could theoretically run a single deduplication job that would be capable of processing about 100 GB per hour. Higher-end systems can be duplicate multiple volumes simultaneously. The theoretical limit is that ninety volumes can be deduplicated simultaneously. In reality however, seventeen volumes at a time is a more realistic expectation from today’s hardware.
It is also worth noting that not every volume type can be deduplicated. Windows Server cannot deduplicate a system volume or a boot volume. Furthermore, the volume cannot reside on removable media and it must not be formatted as ReFS. Cluster shared volumes also cannot be deduplicated.
As I alluded to earlier, there are certain data types that can benefit from the deduplication process more than others. However, there are some types of data that should not be deduplicated. For example, you should not attempt to deduplicate a volume containing files that are constantly open or that change frequently. Similarly, Microsoft does not support deduplicating volumes containing Hyper-V virtual hard disks (for production VMs), although Windows Server 2012 R2 supports the deduplication of Hyper-V-based virtual desktops. You should also avoid deduplicating any volume containing files that are near 1 TB in size.
The biggest restriction with regard to data deduplication is that you cannot deduplicate volumes containing Exchange Server or SQL Server databases. If you attempt to do duplicate these volumes, there is a very real chance that you will corrupt the databases. Although not explicitly spelled out by Microsoft support policies, I recommend that you avoid deduplicating any volume containing a database. Many database applications expect to have control over the way the database pages are stored. Introducing deduplication when the database application expects to have full control over the underlying storage can result in corruption.
The Windows Server native deduplication feature does a great job of helping to conserve physical storage. Even so, it is important to properly plan for deduplication prior to implementing it because there are a number of situations in which the use of deduplication is not appropriate.